News Releases
News releases are listed in chronological order and are archived by year. Sign-up to receive news as it is released using the email and RSS tools below.
| Su | Mo | Tu | We | Th | Fr | Sa |
|---|---|---|---|---|---|---|
| Su | Mo | Tu | We | Th | Fr | Sa |
|---|---|---|---|---|---|---|

-
Jul 22, 2024
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) an industry leader in uranium and rare earth elements production for the energy transition, will hold a conference call on Monday, August 5,...
 Jun 17, 2024
Jun 17, 2024Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company"), a leading U.S. producer of uranium, rare earth elements ("REEs"), and vanadium, is pleased to welcome Debra...
-
Jun 12, 2024
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company"), a leading U.S.-based critical minerals company, announces the results of the election of directors at its...
-
Jun 10, 2024
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company"), a leading U.S. producer of uranium, rare earth elements ("REEs"), and vanadium, is pleased to announce that it...
-
Jun 3, 2024
The Donald Project is an advanced-stage project with the potential to supply approximately 7,000 – 14,000 tonnes of monazite sand in a rare earth element ("REE") concentrate ("REEC") per year to...
-
May 3, 2024
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended March 31, 2024. The Company's Quarterly Report on...
-
Apr 21, 2024
The acquisition will include Base Resources' 100%-owned advanced, world-class Toliara heavy mineral sands project in Madagascar ("Toliara" or the "Project"), which includes a long-life, high-value...
-
Feb 23, 2024
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the year ended December 31, 2023. The Company's Annual Report on Form...
-
Dec 27, 2023
Energy Fuels and Astron Corporation execute non-binding MOU to jointly develop the Donald Mineral Sands Project, a large heavy mineral sand deposit that has the potential to supply Energy Fuels...
-
Dec 21, 2023
Nuclear energy is increasingly being recognized as a clean energy resource globally, while buyers seek non-Russian uranium supply; Energy Fuels is uniquely positioned to immediately increase...
-
Nov 13, 2023
Together with $41.8 million previously paid by enCore, net proceeds from the Note total $64.2 million LAKEWOOD, Colo., Nov. 13, 2023 /CNW/ - Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR)...
-
Nov 3, 2023
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended September 30, 2023. The Company's Quarterly Report...
-
Aug 4, 2023
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended June 30, 2023. The Company's Quarterly Report on...
-
May 27, 2023
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company"), a leading U.S.-based critical minerals company, announces the results of the election of directors at its...
-
May 5, 2023
Conference Call and Webcast on May 9, 2023 The Company sold 300,000 pounds of uranium at a gross margin of 58%, 79,344 pounds of vanadium at a gross margin of 37%, and the Alta Mesa property for a...
-
Mar 8, 2023
Webcast on March 10, 2023 Preparing multiple uranium mines for production, completing profitable sales & developing rare earth refining capacity to power up to 1 million EVs per year by late-2023...
-
Feb 15, 2023
Sale provides Energy Fuels with significant non-dilutive funding for expansion of industry-leading US uranium production and completion of 'Phase 1' rare earth separation circuit. LAKEWOOD, Colo.,...
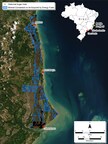 Feb 13, 2023
Feb 13, 2023Acquisition of Bahia Project expected to supply the raw materials needed by the Company's US facility for the production of advanced rare earth materials used in EVs, clean energy, and defense...
-
Dec 16, 2022
DOE program supports critical domestic clean energy & national security priorities Pending membership in DOE HALEU Consortium to support fuel for next generation advanced nuclear reactors...
-
Nov 14, 2022
Non-dilutive sale of asset expected to materially enhance Energy Fuels' balance sheet and help to fund the rapid advancement and expansion of near-term U.S. uranium and rare earth production...
-
Nov 4, 2022
Energy Fuels Inc. (NYSE American: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended September 30, 2022. The Company's quarterly report...
-
Aug 5, 2022
Energy Fuels Inc. (NYSE: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended June 30, 2022. The Company's quarterly report on Form 10-Q...
-
May 25, 2022
Energy Fuels Inc. (NYSE: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company"), the leading uranium producer in the United States, announces the results of the election of directors at its annual...
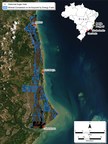 May 19, 2022
May 19, 2022~58.3 square mile (~37,300 acre) heavy mineral sand position has potential to feed the Company's White Mesa Mill with rare earth element and uranium bearing natural monazite sand for decades...
-
May 16, 2022
Energy Fuels Inc. (NYSE: UUUU) (TSX: EFR) ("Energy Fuels" or the "Company") today reported its financial results for the quarter ended March 31, 2022. The Company's annual report on Form 10-K has...